llama.cpp 在ubuntu上的安装部署
本次部署踩坑总结
| ❌ 下载链接失效 | 官方改了文件名,9 字节的假文件 | 用正确文件名 llama-b8913-bin-ubuntu-vulkan-x64.tar.gz |
| ❌ 进入目录报错 | 解压后是 llama-b8913,不是预期名称 | ls 查看实际目录 |
| ❌ huggingface CLI 报错 | typer 版本冲突,hf 命令无法使用 | 直接用 curl + hf-mirror.com 下载 |
| ✅ 国内下载慢 | huggingface.co 访问慢 | 用 hf-mirror.com 镜像站 |
两卡并联总显存 32GB,完全够用!
模型选择建议
| Q4_K_XL | ~21GB | ✅ 能装下(还剩 ~11GB) | ⭐ 推荐 |
| Q4_K_M | ~18GB | ✅ 轻松装下(还剩 ~14GB) | ⭐⭐ 显存更宽裕 |
单卡 16GB 就够装 Q4_K_XL 了,两卡可以用于其他任务或加速
# 单卡运行(直接指定第一张卡)
./llama-cli -m ./models/Qwen3.6-35B-A3B-UD-Q4_K_XL.gguf -p "你好" -ngl 99 -lb 0
# 两卡并联(让 llama.cpp 自动分配到两张卡)
./llama-cli -m ./models/Qwen3.6-35B-A3B-UD-Q4_K_XL.gguf -p "你好" -ngl 99
测试与验证:
./llama-cli -m ./models/Qwen3.6-35B-A3B-UD-Q4_K_XL.gguf -p "用中文回答:你好" -ngl 99
ollama 测试与验证:
ollama run qwen3.6:35b "hi" --verbose 简单评测
llama.cpp (Vulkan) vs Ollama 实测对比
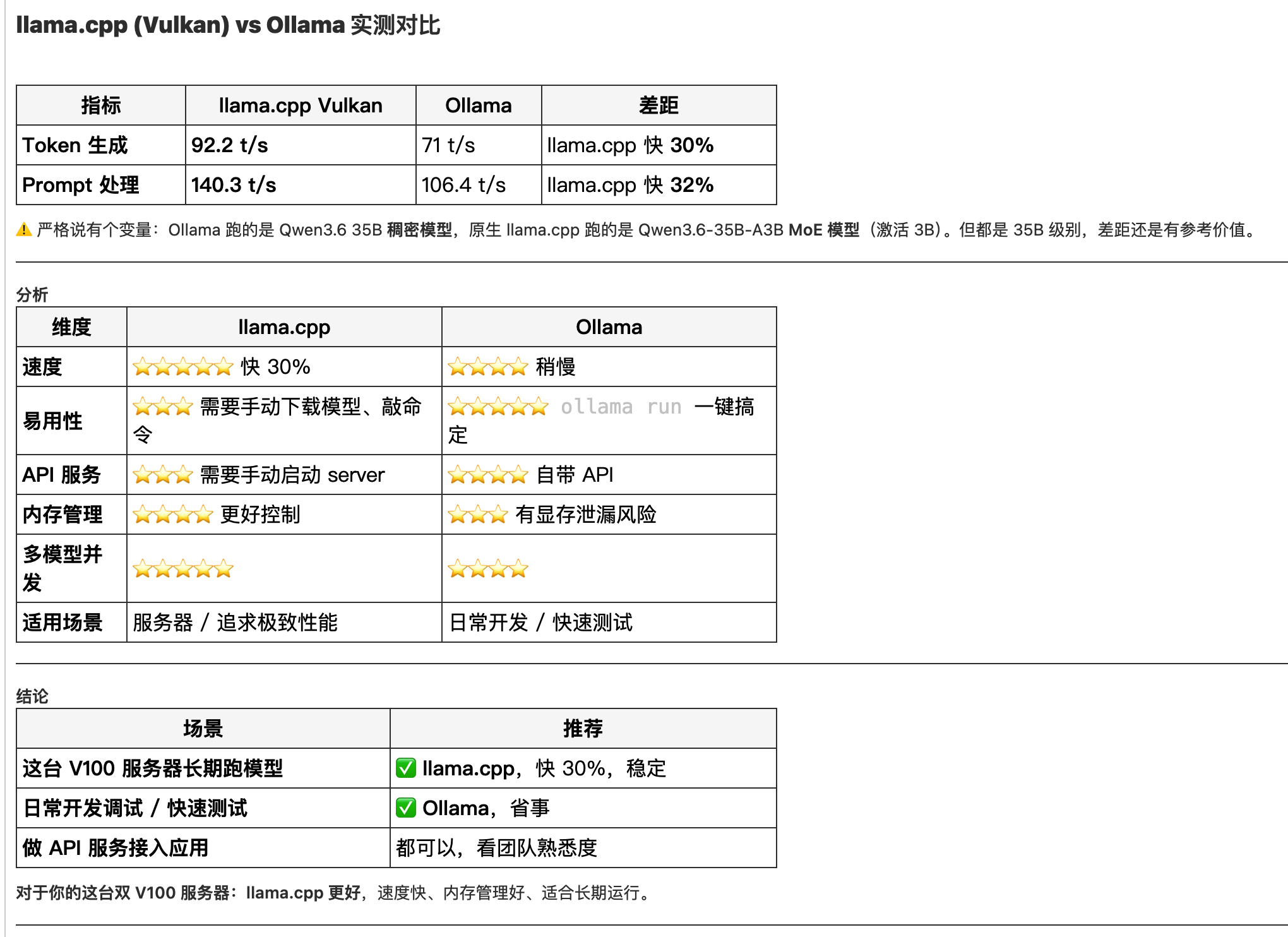
| Token 生成 | 92.2 t/s | 71 t/s | llama.cpp 快 30% |
| Prompt 处理 | 140.3 t/s | 106.4 t/s | llama.cpp 快 32% |
⚠️ 严格说有个变量:Ollama 跑的是 Qwen3.6 35B 稠密模型,原生 llama.cpp 跑的是 Qwen3.6-35B-A3B MoE 模型(激活 3B)。但都是 35B 级别,差距还是有参考价值。
分析
| 速度 | ⭐⭐⭐⭐⭐ 快 30% | ⭐⭐⭐⭐ 稍慢 |
| 易用性 | ⭐⭐⭐ 需要手动下载模型、敲命令 | ⭐⭐⭐⭐⭐ ollama run 一键搞定 |
| API 服务 | ⭐⭐⭐ 需要手动启动 server | ⭐⭐⭐⭐ 自带 API |
| 内存管理 | ⭐⭐⭐⭐ 更好控制 | ⭐⭐⭐ 有显存泄漏风险 |
| 多模型并发 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 适用场景 | 服务器 / 追求极致性能 | 日常开发 / 快速测试 |
结论
| 这台 V100 服务器长期跑模型 | ✅ llama.cpp,快 30%,稳定 |
| 日常开发调试 / 快速测试 | ✅ Ollama,省事 |
| 做 API 服务接入应用 | 都可以,看团队熟悉度 |
对于你的这台双 V100 服务器:llama.cpp 更好,速度快、内存管理好、适合长期运行。
需要帮你配置 API 服务吗?这样可以让其他机器调用这台服务器的模型。
llama.cpp 启动后GPU占用:
Ubuntu + llama.cpp 部署指南
硬件环境:双卡 NVIDIA V100 16GB × 2
系统:Ubuntu (Noble)
记录时间:2026-04-24
一、安装依赖
sudo apt update
sudo apt install build-essential cmake git libcurl4-openssl-dev
二、下载预编译二进制
❌ 错误方式(旧链接已失效)
# 这个链接已经不存在了,会下载到 9 字节的错误页面
curl -L https://github.com/ggml-org/llama.cpp/releases/latest/download/llama-cli-ubuntu-x86_64.tar.gz
✅ 正确方式
版本下载链接适用场景
CPUhttps://github.com/ggml-org/llama.cpp/releases/download/b8913/llama-b8913-bin-ubuntu-x64.tar.gz无 GPU / CPU 推理
Vulkanhttps://github.com/ggml-org/llama.cpp/releases/download/b8913/llama-b8913-bin-ubuntu-vulkan-x64.tar.gzNVIDIA / AMD / Intel 显卡
# 下载 Vulkan 版本(推荐,支持 V100)
curl -L https://github.com/ggml-org/llama.cpp/releases/download/b8913/llama-b8913-bin-ubuntu-vulkan-x64.tar.gz \
-o llama.tar.gz
tar -xzf llama.tar.gz
# 解压后目录是 llama-b8913(不是 llama-b8913-bin-ubuntu-x64)
cd llama-b8913
三、下载模型
⚠️ huggingface-cli 已废弃
# 这个命令已经不可用
huggingface-cli download ... # ❌ 废弃
hf download ... # ❌ typer 版本冲突,报错
✅ 正确方式:使用国内镜像
mkdir -p ./models
# 方式1:使用 hf-mirror(推荐,国内快)
curl -L "https://hf-mirror.com/<用户名>/<模型名>/resolve/main/<文件名.gguf>" \
-o ./models/<文件名.gguf>
# 方式2:直接 wget
wget -P ./models "<下载链接>"
下载示例
测试用小模型 TinyLlama(637MB):
curl -L "https://hf-mirror.com/TheBloke/TinyLlama-1.1B-Chat-v1.0-GGUF/resolve/main/tinyllama-1.1b-chat-v1.0.Q4_K_M.gguf" \
-o ./models/tinyllama-1.1b-chat-v1.0.Q4_K_M.gguf
生产用模型 Qwen3.6-35B MoE(~21GB):
curl -L "https://hf-mirror.com/unsloth/Qwen3.6-35B-A3B-GGUF/resolve/main/Qwen3.6-35B-A3B-UD-Q4_K_XL.gguf" \
-o ./models/Qwen3.6-35B-A3B-UD-Q4_K_XL.gguf
四、运行模型
命令行交互
./llama-cli -m ./models/<模型名.gguf> -p "你的问题" -ngl 99
● -ngl 99:将模型尽可能加载到 GPU,不够时自动回退 CPU
● 运行后会显示 GPU 显存使用情况
启动 API 服务器
./llama-server -m ./models/<模型名.gguf> -c 4096 --host 0.0.0.0 --port 8080 -ngl 99
启动后访问 http://<服务器IP>:8080,API 格式兼容 OpenAI:
curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model": "qwen", "messages": [{"role": "user", "content": "你好"}]}'
五、踩坑记录
坑1:预编译包文件名变了
● 症状:下载的文件只有 9 字节,是个重定向页面
● 原因:llama.cpp 官方在 b8913 版本改了打包格式
● 解决:用上表中的正确文件名
坑2:解压后目录名不是预期
● 症状:cd llama-b8913-bin-ubuntu-x64 报错"No such file or directory"
● 原因:实际解压后是 llama-b8913
● 解决:ls 查看实际目录名
坑3:huggingface-cli / hf 命令不可用
● 症状:Typer.__init__() got an unexpected keyword argument 'suggest_commands'
● 原因:typer 版本冲突,huggingface_hub CLI 有兼容性问题
● 解决:直接用 curl / wget 从 hf-mirror.com 下载,绕过 CLI
坑4:huggingface.co 国内访问慢
● 症状:下载超时或速度极慢
● 解决:使用 hf-mirror.com 镜像站,国内速度快很多
六、双卡 V100 实测数据
运行 TinyLlama 1B Q4_K_M 的显存分配:
Vulkan1 (V100-SXM2-16GB): 16384 = 13592 free | 277 self (已用 ~2.7GB)
Vulkan2 (V100-SXM2-16GB): 16384 = 15048 free | 435 self (已用 ~0.4GB)
推理速度:
● Prompt 处理:476-511 t/s
● Token 生成:245-338 t/s
● 总耗时:约 19 秒(含 16 秒模型加载 + 3 秒推理)
七、常用命令速查
任务命令
下载模型curl -L "<hf-mirror链接>" -o ./models/<名>
交互对话./llama-cli -m ./models/<名> -p "问题" -ngl 99
启动 API./llama-server -m ./models/<名> -c 4096 -ngl 99
查看显存./llama-cli -m <模型> ... 退出时会打印显存分配
查看帮助./llama-cli --help / ./llama-server --help
八、推荐模型(2026年)
模型大小量化推荐场景
TinyLlama 1B~637MBQ4_K_M快速测试 / CPU 机器
Qwen2.5 7B~4.2GBQ4_K_M通用对话 / 低显存
Qwen3.6-35B-A3B MoE~21GBQ4_K_XL⭐ 编程 / 高质量推理(V100 推荐)
Llama 3.1 70B~40GBQ4_K_M超大模型 / 需要更高配置