再分析 mysql 之 insert into xxx select * from yyy 的疑问
再分析 mysql 之 insert into xxx select * from yyy , 之前以为自己已经很明白此语句的优劣, 结果同事临时问时, 却对底层原理的级的说明开始不确定, 进而出现了模糊的感觉, 因此, 有必要做一个彻底的明了:
疑问1.
明确的说法 insert into xxx select * from yyy 一定会导致 yyy 引起表锁, 而如果 insert into xxx select * from yyy where id=123 会是什么及别的锁呢?
证明1:
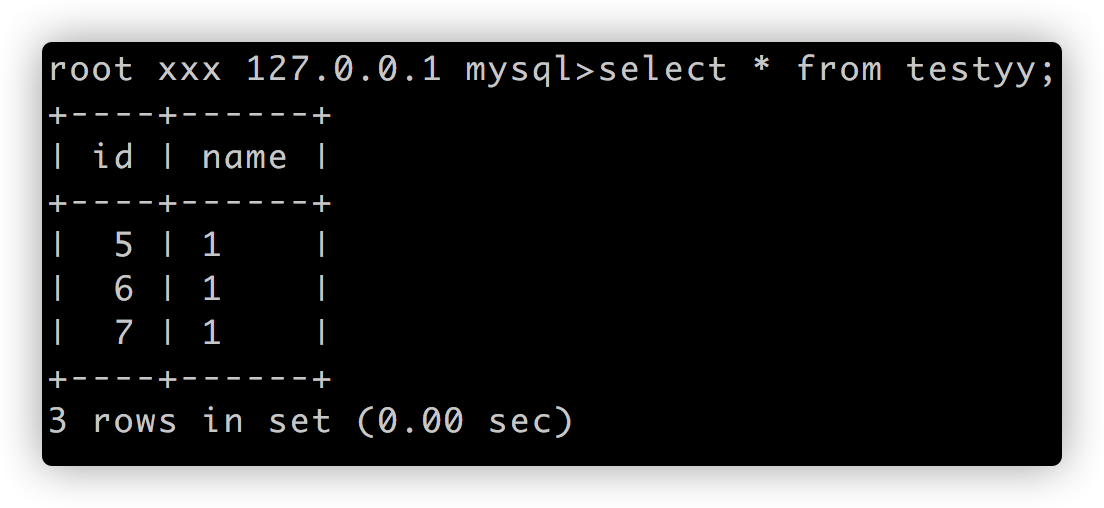
执行语句:
当前数据状态: select * from testyy; 为3条数据, 而testxx 无数据:
begin;
insert into testxx select * from testyy
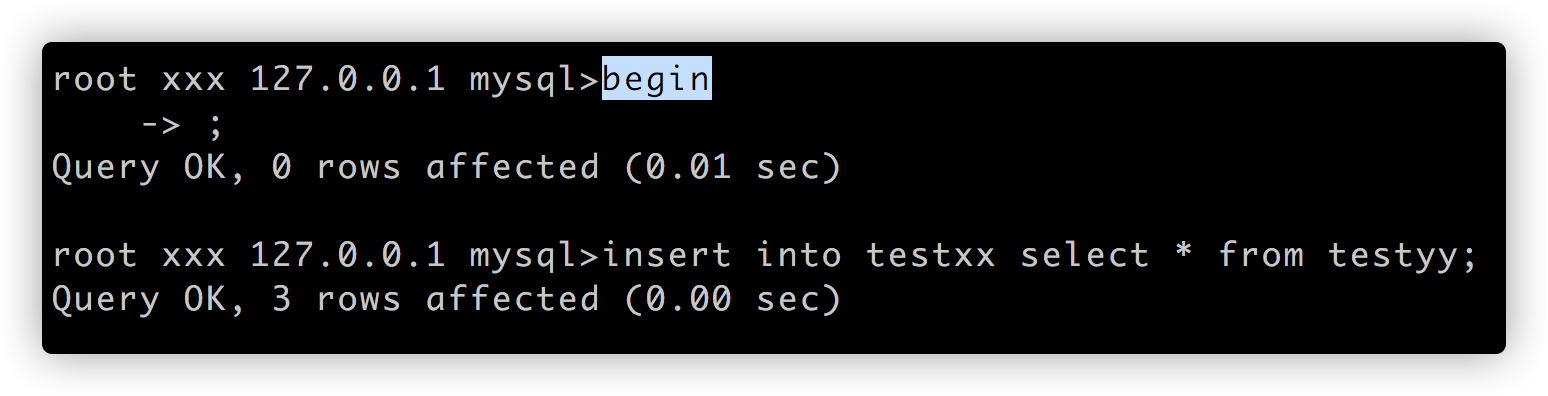
此时更新数据和插入数据 执行:
update testyy set name=123 where id=5
insert into testyy values(9,'okok');
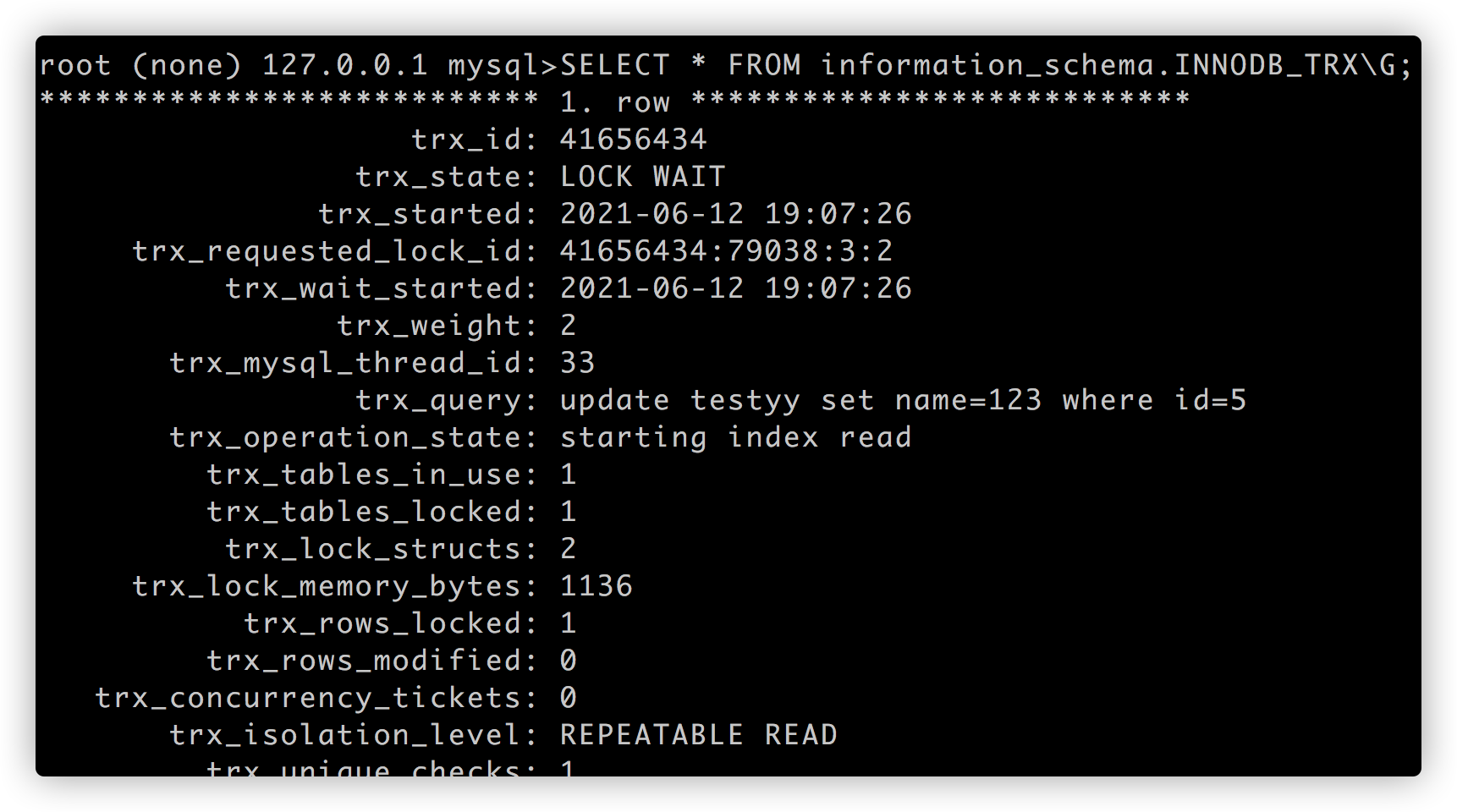
使用 SELECT * FROM information_schema.INNODB_TRX\G; 查看锁表状态:
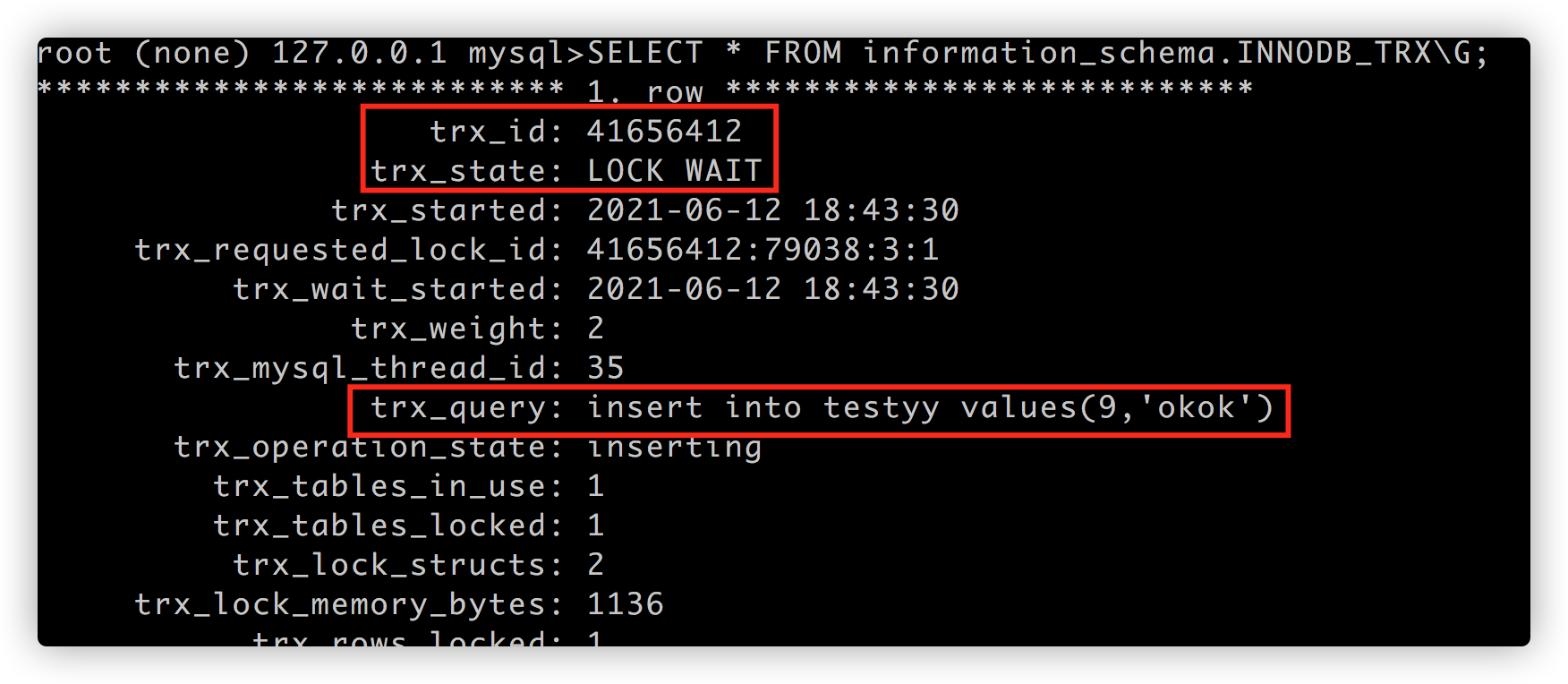
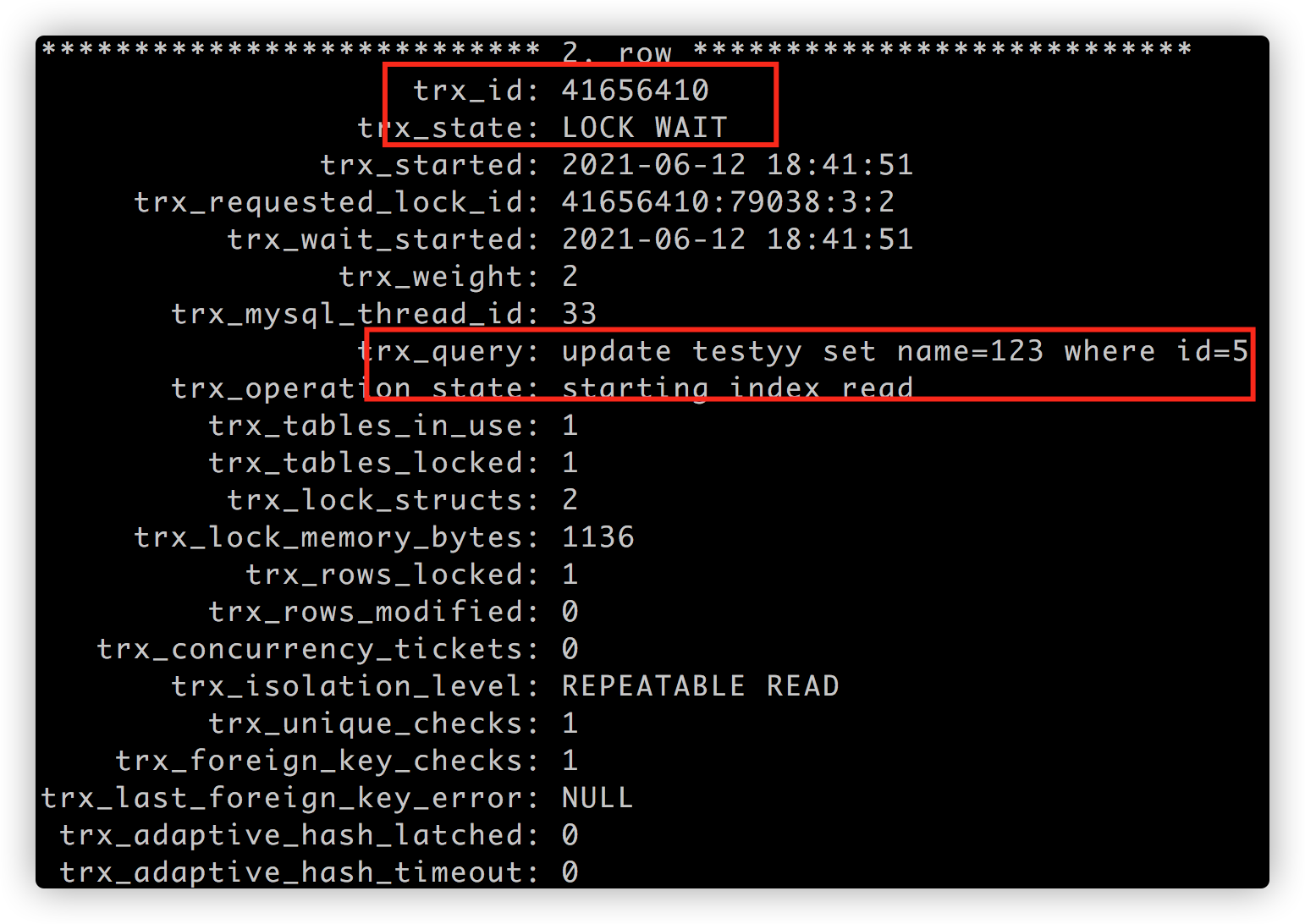
结论: 类似 insert into testxx select * from testyy 一定是存在表级锁, 这是绝对无疑问的;
测试:
begin;
insert into testxx select * from testyy where id in (5,6);
存在锁:
update testyy set name=123 where id=5
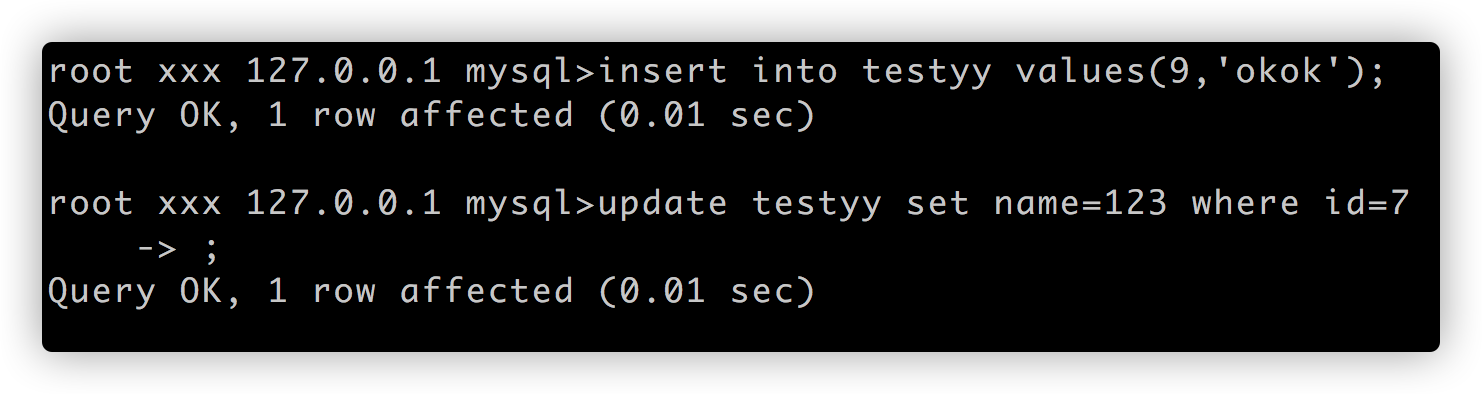
无锁:
update testyy set name=123 where id=7
insert into testyy values(9,'okok');
疑问2.
对于此语句在 binlog_format 在 STATEMENT, ROW, MIXED 会记录成什么样子, 通过binlog进行数据恢复时会有什么问题:
binlog_format 为 STATEMENT 格式时:
执行语句:
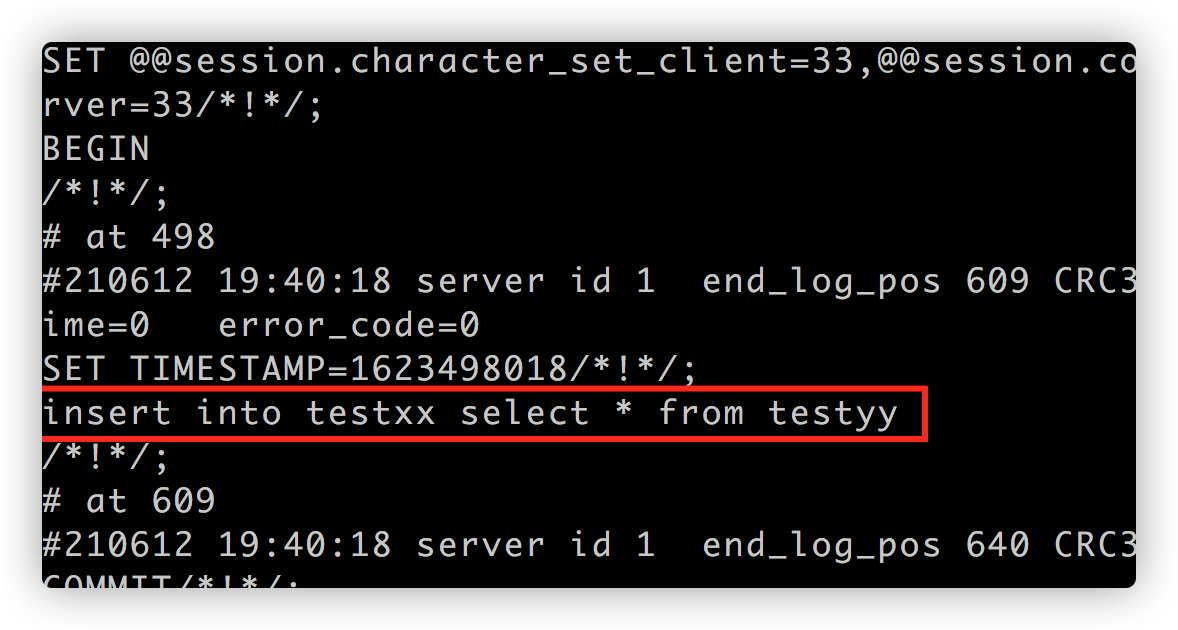
insert into testxx select * from testyy;
查看binlog: 例如:
mysqlbinlog mysql-bin.000109 -vv
当为SATEMENT 时会将sql直接记录, 此种模式的问题在于, 如果此时进行binlog进行恢复此时的数据, 结果可想而知, 因数据的主键的唯一, 将导致恢复数据异常:
binlog_format 为 MIXED 格式时:
执行语句:
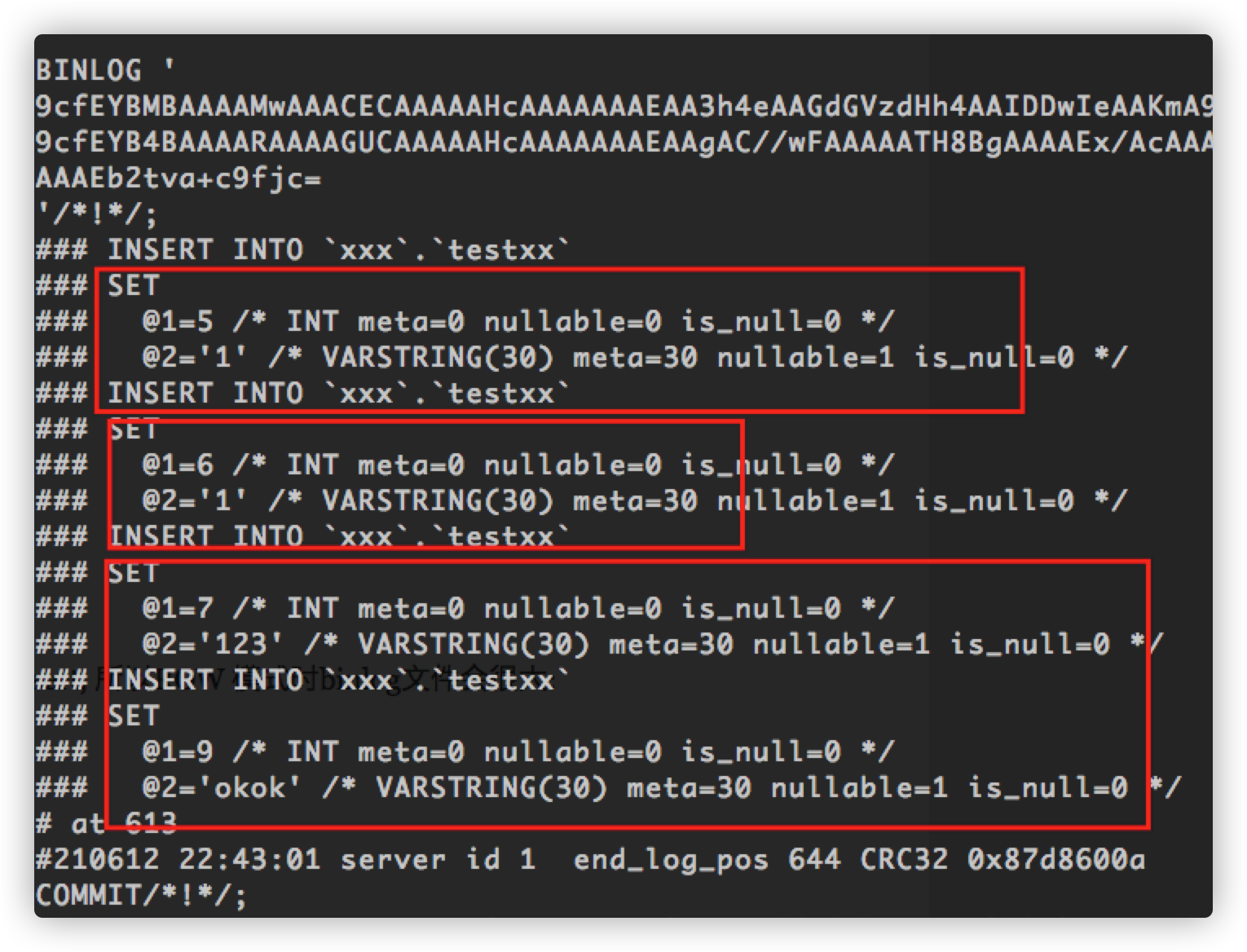
insert into testxx select * from testyy;
查看binlog: 例如:
mysqlbinlog mysql-bin.000109 -vv
当为MIXED 时会将分解出多个insert 进行记录到binlog:
binlog_format 为 ROW 格式时: 记录的binlog如下, 会分解为多个insert, 所以ROW 模式时binlog文件会很大:
执行语句:
insert into testxx select * from testyy;
查看binlog: 例如:
mysqlbinlog mysql-bin.000109 -vv
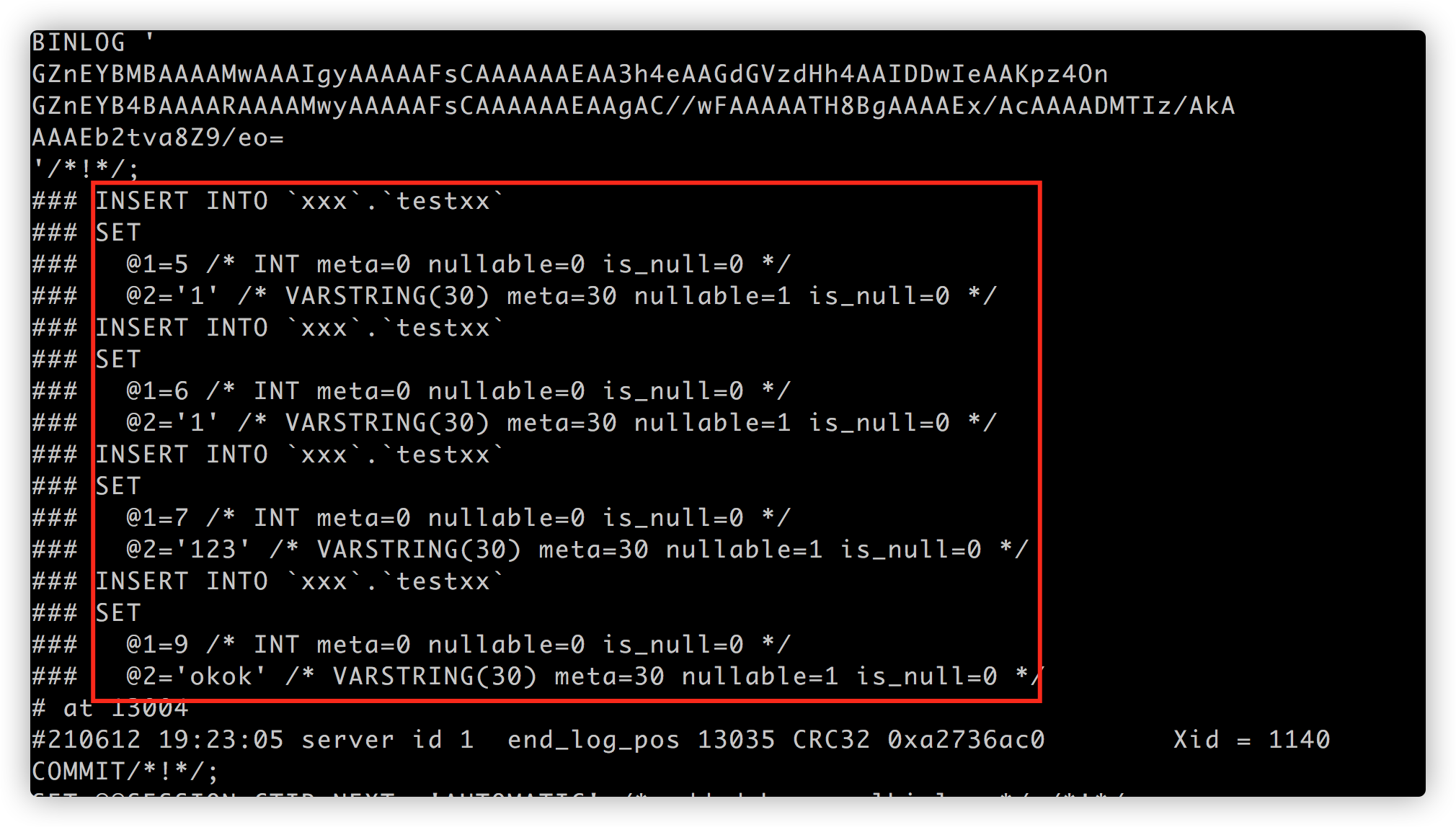
疑问: 对于mixed 和 row 有什么区别呢:
执行语句:
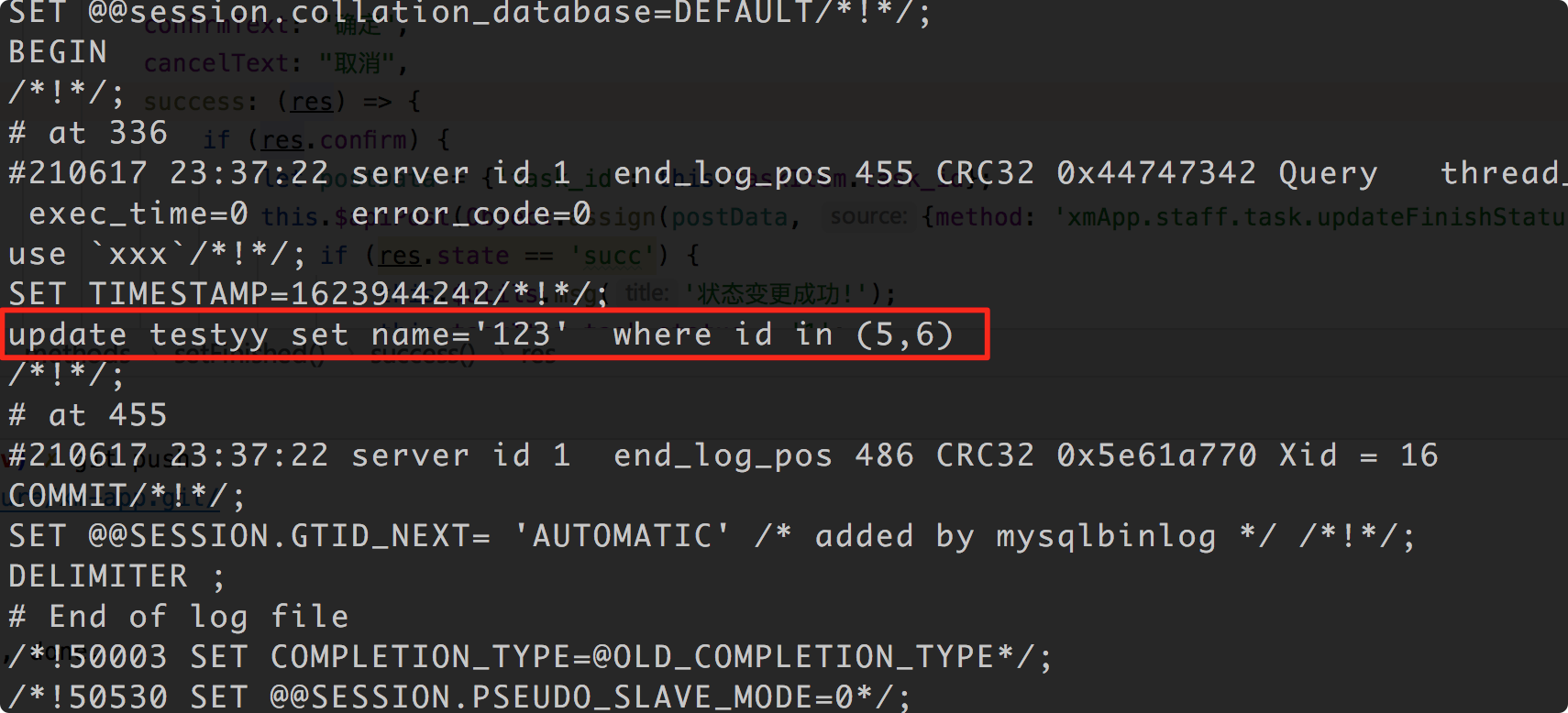
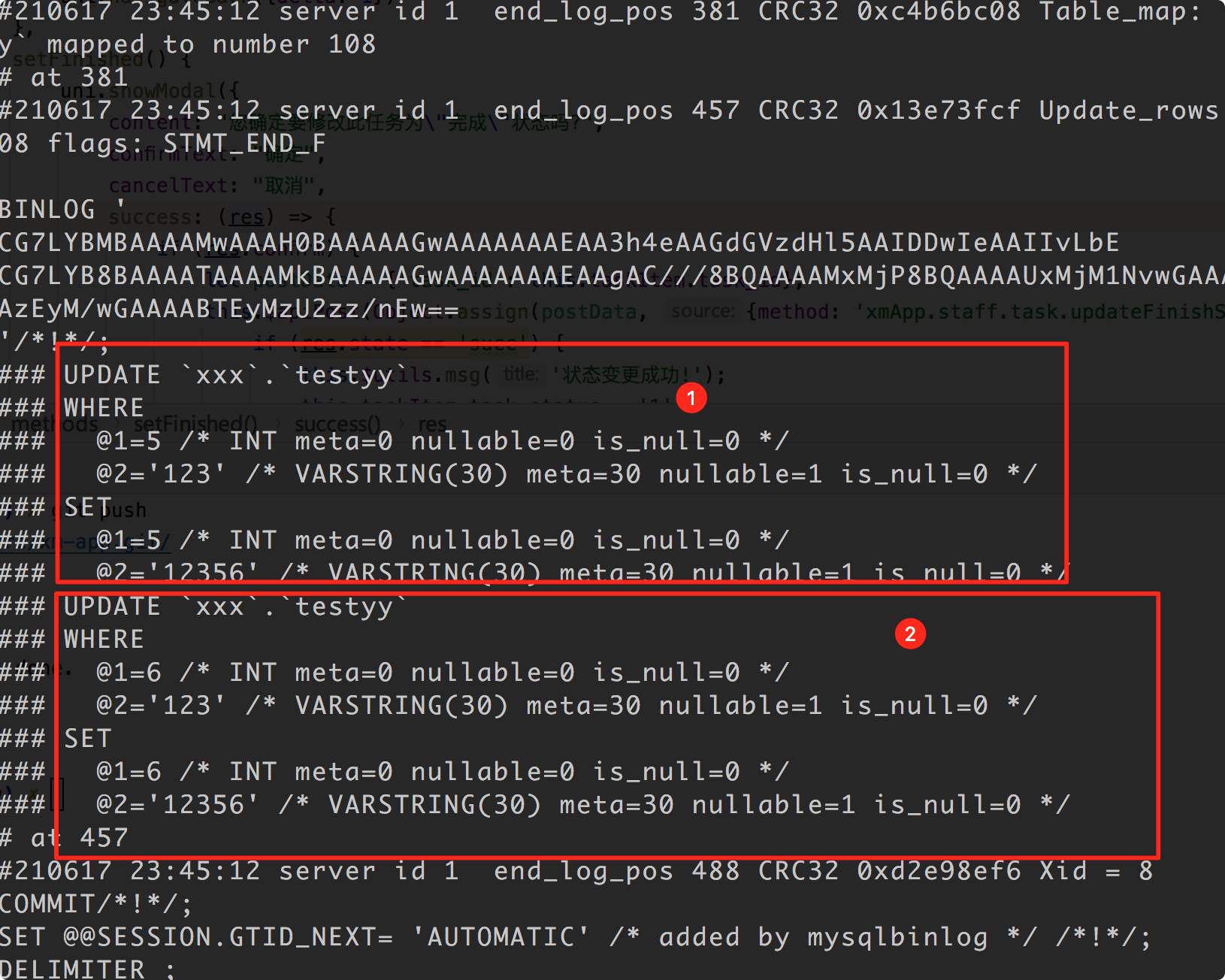
update testyy set name='12356' where id in (5,6);
mixed 时binlog的记录: 原句记录, 这和statement是一样的:
而使用ROW时: binlog记录: 被拆成行分别记录, 可以说row对所有的执行都是记录到行变更的, 包含update的in, delete 的in, 存储过程等场景:
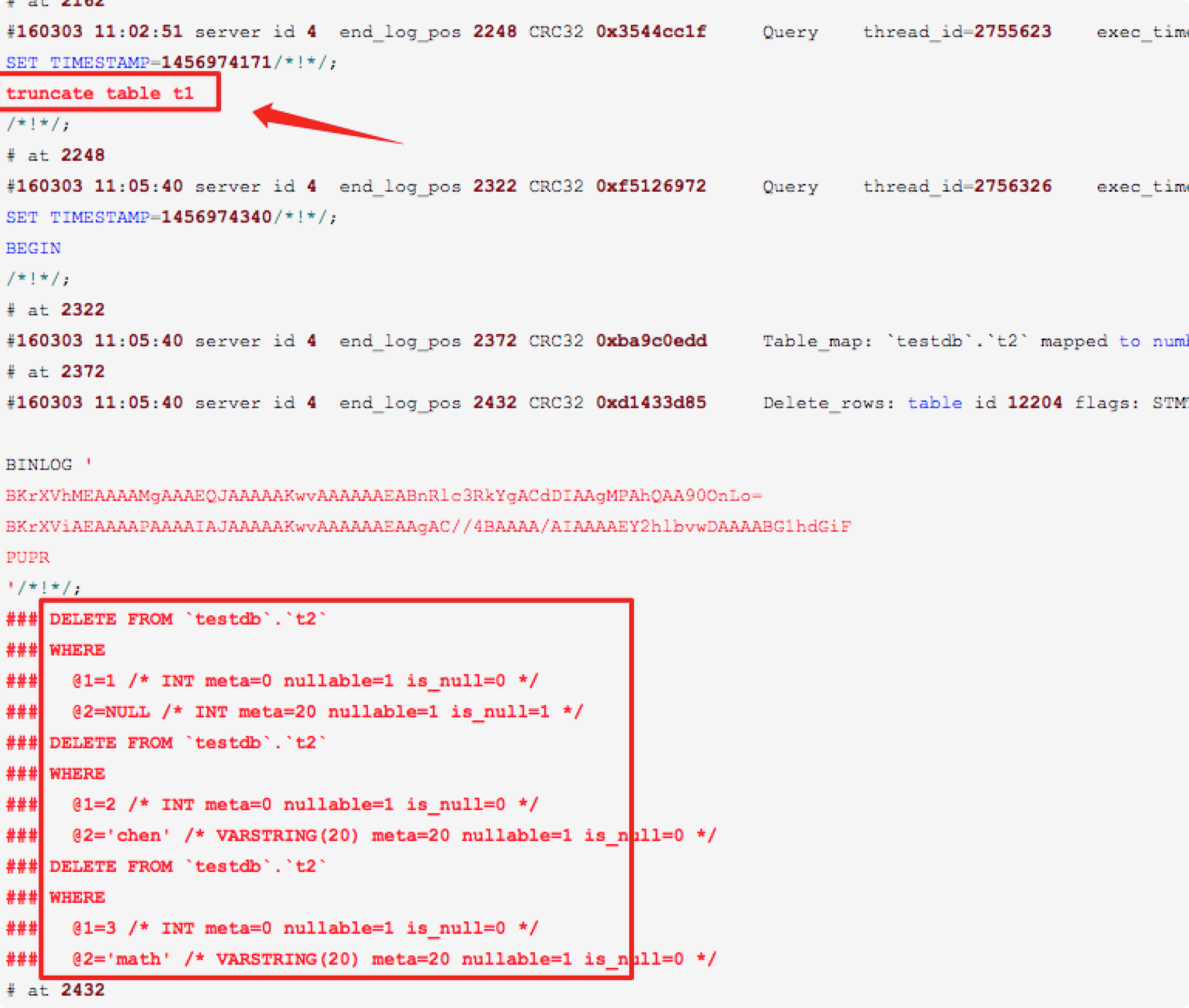
其它: 20210803补充:
truncate 与delete对比
truncate 会直接记录 truncate 表语句, 此操作无明细语句记录, 是无法通过bin-log进行数据还原的!
2. slave 开启多线程同步:
如: 开启8线程:
STOP SLAVE SQL_THREAD;SET GLOBAL slave_parallel_type='LOGICAL_CLOCK';SET GLOBAL slave_parallel_workers=8;START SLAVE SQL_THREAD;
效果如图:
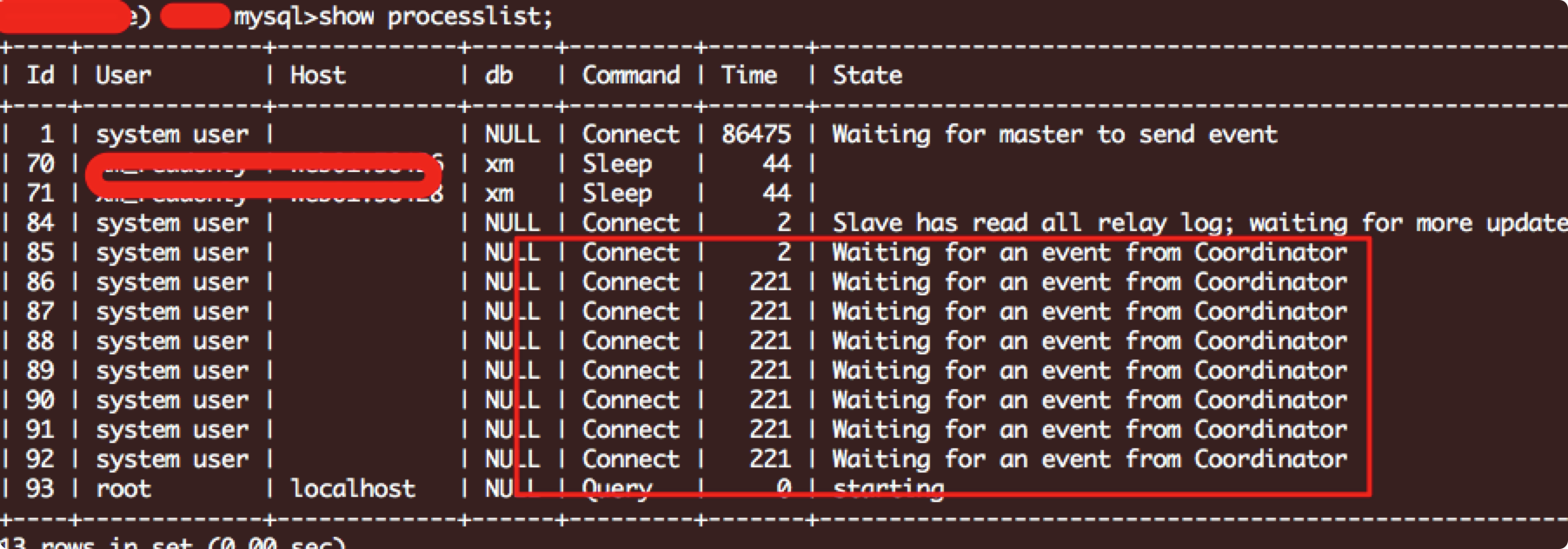
综上, 理解起来更直观了!
以下来自: https://www.cnblogs.com/langtianya/p/5504774.html
mysql中binlog_format模式与配置详解
mysql复制主要有三种方式:基于SQL语句的复制(statement-based replication, SBR),基于行的复制(row-based replication, RBR),混合模式复制(mixed-based replication, MBR)。对应的,binlog的格式也有三种:STATEMENT,ROW,MIXED。
① STATEMENT模式(SBR)
每一条会修改数据的sql语句会记录到binlog中。优点是并不需要记录每一条sql语句和每一行的数据变化,减少了binlog日志量,节约IO,提高性能。缺点是在某些情况下会导致master-slave中的数据不一致(如sleep()函数, last_insert_id(),以及user-defined functions(udf)等会出现问题)
② ROW模式(RBR)
不记录每条sql语句的上下文信息,仅需记录哪条数据被修改了,修改成什么样了。而且不会出现某些特定情况下的存储过程、或function、或trigger的调用和触发无法被正确复制的问题。缺点是会产生大量的日志,尤其是alter table的时候会让日志暴涨。
③ MIXED模式(MBR)
以上两种模式的混合使用,一般的复制使用STATEMENT模式保存binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存binlog,MySQL会根据执行的SQL语句选择日志保存方式。
binlog复制配置
在mysql的配置文件my.cnf中,可以通过一下选项配置binglog相关
代码如下复制代码
binlog_format = MIXED //binlog日志格式,mysql默认采用statement,建议使用mixed
log-bin = /data/mysql/mysql-bin.log //binlog日志文件
expire_logs_days = 7 //binlog过期清理时间
max_binlog_size = 100m //binlog每个日志文件大小
binlog_cache_size = 4m //binlog缓存大小
max_binlog_cache_size = 512m //最大binlog缓存大小
三 MIXED说明
对于执行的SQL语句中包含now()这样的时间函数,会在日志中产生对应的unix_timestamp()*1000的时间字符串,slave在完成同步时,取用的是sqlEvent发生的时间来保证数据的准确性。另外对于一些功能性函数slave能完成相应的数据同步,而对于上面指定的一些类似于UDF函数,导致Slave无法知晓的情况,则会采用ROW格式存储这些Binlog,以保证产生的Binlog可以供Slave完成数据同步。
现在来比较以下 SBR 和 RBR 2中模式各自的优缺点:
SBR 的优点:
历史悠久,技术成熟
binlog文件较小
binlog中包含了所有数据库更改信息,可以据此来审核数据库的安全等情况
binlog可以用于实时的还原,而不仅仅用于复制
主从版本可以不一样,从服务器版本可以比主服务器版本高
SBR 的缺点:
不是所有的UPDATE语句都能被复制,尤其是包含不确定操作的时候。
调用具有不确定因素的 UDF 时复制也可能出问题
使用以下函数的语句也无法被复制:
* LOAD_FILE()
* UUID()
* USER()
* FOUND_ROWS()
* SYSDATE() (除非启动时启用了 --sysdate-is-now 选项)
INSERT ... SELECT 会产生比 RBR 更多的行级锁
复制需要进行全表扫描(WHERE 语句中没有使用到索引)的 UPDATE 时,需要比 RBR 请求更多的行级锁
对于有 AUTO_INCREMENT 字段的 InnoDB表而言,INSERT 语句会阻塞其他 INSERT 语句
对于一些复杂的语句,在从服务器上的耗资源情况会更严重,而 RBR 模式下,只会对那个发生变化的记录产生影响
存储函数(不是存储过程)在被调用的同时也会执行一次 NOW() 函数,这个可以说是坏事也可能是好事
确定了的 UDF 也需要在从服务器上执行
数据表必须几乎和主服务器保持一致才行,否则可能会导致复制出错
执行复杂语句如果出错的话,会消耗更多资源
RBR 的优点:
任何情况都可以被复制,这对复制来说是最安全可靠的
和其他大多数数据库系统的复制技术一样
多数情况下,从服务器上的表如果有主键的话,复制就会快了很多
复制以下几种语句时的行锁更少:
* INSERT ... SELECT
* 包含 AUTO_INCREMENT 字段的 INSERT
* 没有附带条件或者并没有修改很多记录的 UPDATE 或 DELETE 语句
执行 INSERT,UPDATE,DELETE 语句时锁更少
从服务器上采用多线程来执行复制成为可能
RBR 的缺点:
binlog 大了很多
复杂的回滚时 binlog 中会包含大量的数据
主服务器上执行 UPDATE 语句时,所有发生变化的记录都会写到 binlog 中,而 SBR 只会写一次,这会导致频繁发生 binlog 的并发写问题
UDF 产生的大 BLOB 值会导致复制变慢
无法从 binlog 中看到都复制了写什么语句
当在非事务表上执行一段堆积的SQL语句时,最好采用 SBR 模式,否则很容易导致主从服务器的数据不一致情况发生
另外,针对系统库 mysql 里面的表发生变化时的处理规则如下:
如果是采用 INSERT,UPDATE,DELETE 直接操作表的情况,则日志格式根据 binlog_format 的设定而记录
如果是采用 GRANT,REVOKE,SET PASSWORD 等管理语句来做的话,那么无论如何都采用 SBR 模式记录
注:采用 RBR 模式后,能解决很多原先出现的主键重复问题。